


Intro
When it comes to Kubernetes environments, teams are finding themselves unable to get the security posture they want in a practical amount of time using the cloud native security tools available today. A Kubernetes-first approach, as recently launched by KSOC with Automated Risk Triage and threat vectors, connects the broad set of components of Kubernetes together in real-time for earlier detection of attacks and better prioritization of risk in Kubernetes environments. This approach not only reduces noise and alerts, it requires less rework from engineering, offering the industry’s first true solution to the inefficiency in cloud native security. With a Kubernetes-first perspective of cloud native security, the time it takes to prioritize risk and detect incidents in Kubernetes environments can literally fit inside your next coffee break.
Download the Kubernetes Security Master Guide
Cloud native security has become too inefficient
Cloud native applications have fundamentally changed how teams secure applications, as development teams and engineering become more responsible for baking security in from day one and security teams must get up to speed with the cloud, as well as a whole host of new tools and technologies.
After nearly a decade of container technology, cloud native security is beginning to show cracks. While tools have improved and the options have expanded, there is still a major outstanding level of efficiency that has yet to be addressed, leaving teams in a lurch. Today, if you have any responsibility for securing cloud native applications, you are faced with choosing from a suite of tools that create vicious cycles of inefficiency.
How many times have your teams wondered if you’re wasting your time prioritizing vulnerabilities in shift-left that won’t even reach production? Vulnerability management for containerized applications is primarily a shift-left exercise, where fixes are pushed earlier and earlier into application development. But those same developers responsible for making those security fixes are the ones responsible for pushing out the code that underlies business critical applications driving the bottom line for businesses. And the list of vulnerabilities is not going down any time soon. There are many tools and features out there that connect runtime data to vulnerabilities to better prioritize. This validates the inefficiencies of the current scenario, though it doesn’t yet solve the entire problem of inefficiency.
Another example is the time it takes teams to implement a single tool. We commonly see teams taking years on this endeavor. Reasons for the delay include complexity of the toolset involved, lack of skilled practitioners, the difficulty of getting permission from engineering or development to make changes in the CI/CD pipeline or installing a tool that might break production (e.g. CI/CD checks, runtime policies or admission control).
The impasse, friction and difficulty between security and engineering teams is so real that security would sometimes rather buy a tool that only provides visibility, with zero enforcement or protective capability, as long as it’s something they don’t have to work with engineering.
The time and effort involved in dealing with these and other issues create a huge opportunity cost across other attack vectors and projects. But perhaps worst of all, teams are now accustomed to an inability to get their security posture where they want it, in a practical amount of time. Overall, the prevailing sentiment from many teams is one of defeat, wishing they could cover every attack surface and apply world-class security capabilities to every part of the application lifecycle, which most teams know is out of reach.
These days, the sizes of teams are not increasing, they are decreasing, making security seem like a far off possibility if effective security rests on the ability to hire more. Different teams work on different parts of the application lifecycle, and each feels they have a role to play but aren’t able to do everything because they lack enough people or don’t have enough budget to get all the tools.
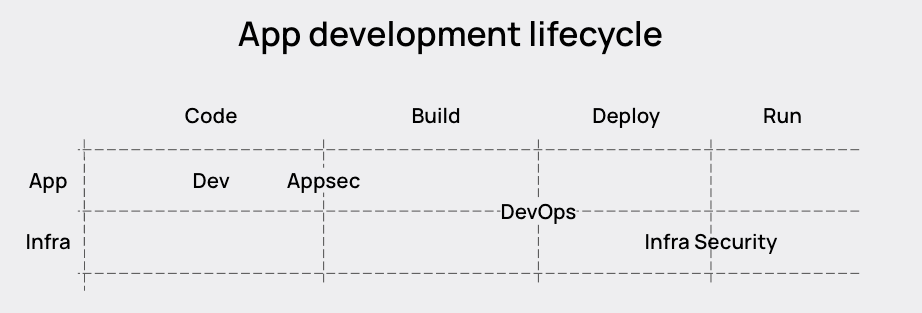
Any market guide from an analyst will show a perspective of the application development lifecycle that is fragmented and separated. There has been a lot of talk in the industry about putting these capabilities all together, namely with the Cloud Native Application Protection Platform, but very little analysis of how to make connections across the different capabilities seen below.
Instead of making connections, in some cases vendors are actually creating false boundaries between the different parts of the lifecycle. For example, Cloud Security Posture Management (CSPM) and Kubernetes Security Posture Management (KSPM) are generally not done in real-time; they are done on polling intervals. For CSPM, that’s not as bad of an issue if you don’t have a Kubernetes environment, because the configurations don’t change so quickly. But for environments with Kubernetes, and KSPM, that creates an inefficient scenario where the Kubernetes configurations are not tied to the Kubernetes lifecycle. By the time you go to remediate the issue, there is a high likelihood, based on the average container lifetime of less than 5 minutes, that the workload and associated misconfiguration have disappeared. What you are left with is inactionable noise.
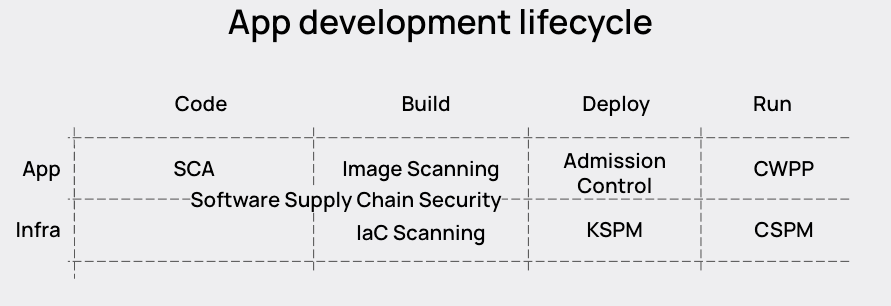
How to improve efficiency in cloud native security
The first obvious solution is to get more done with the same team. If we can connect the application level in the diagram above to the infrastructure level so it’s clear what is running where at any given time, we benefit from an added layer of natural context. And then if we can triage risks using that data, we can get better accuracy and spend less time prioritizing risk.
We can also transform security’s focus on enforcement to a focus on providing the best security signal and drawing engineering into the problem-solving process. Security could be the team that enables other teams to understand how all the various risk factors work together. This is not too far from what security is responsible for today with SOC and SIEM initiatives; the responsibility would just be taken to a new level with cloud native security.
We can also stop trying to do the impossible job of covering all security issues across all attack surfaces with too few people. Instead, we can look for the one place that, if security is done right, might be able to shield us from the risk in other parts of the application development lifecycle.
Kubernetes: a likely or unlikely candidate to solve for inefficiency?
Most people using Kubernetes would not think of it as a tool to simplify anything. It is generally complicated and sometimes the way it’s put together just doesn’t make sense. However, because of its central role in the deployment and management of cloud native applications, it is the best candidate to solving our problem of efficiency in cloud native security.
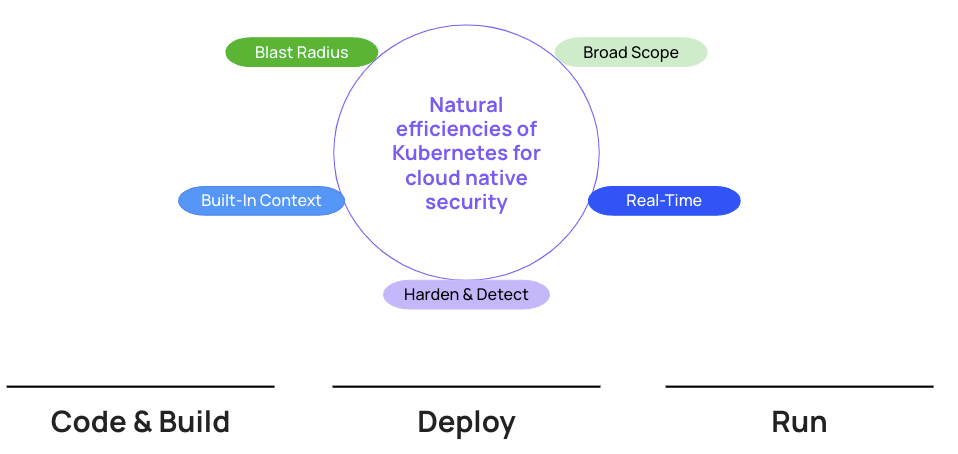
Connect infrastructure to the application layer
First, Kubernetes can be the medium through which we connect the infrastructure to the application layer of a cloud native application.
- Real-time by default: The Kubernetes lifecycle is real-time by default. Kubernetes directs the workload lifecycle and there is also a lifecycle associated with the Kubernetes API related to Role-Based Access Control (RBAC) and other API elements. Containers in Kubernetes live for less than 5 minutes on average, and Kubernetes sees all of this. If you truly have a connected, real-time view of Kubernetes there is no polling interval, no space in which an attacker can sneak by. That makes a huge difference for efficiency in terms of both accuracy and being able to prioritize risk.
- Broad scope: Kubernetes has the broadest scope of any tool in the cloud native application development lifecycle (that’s why every cloud native security vendor says they do Kubernetes Security, and they’re technically not wrong). It touches the Continuous Integration tools, the images you deploy, the network, the public cloud, runtime, IAM permissions and more. Not only does it touch these things, it is the director of these things, determining which process to invoke, which container to deploy, which image registry to use, which cloud service to use. If you are securing Kubernetes holistically, you are including all of these things as well as securing the orchestrator itself, which has its own set of security risks to address.
- Built-in context, source of truth: As mentioned before, Kubernetes is the ultimate source of truth for what is deployed. Kubernetes is the director of the apps, process, cloud services that are deployed and more. These connections are hugely valuable pieces of information to understanding what is actually running, hence what should be prioritized as a fix in shift-left or what is a true indicator of compromise in runtime. But all these different contexts must be combined together under one roof in real-time.
Find a more efficient line of defense
Kubernetes has a location and purpose in the application development lifecycle that shields applications from risk introduced in other places.
- Blast radius control: Hardened clusters are an efficient line of defense against the blast radius of container vulnerabilities. If you have a vulnerable web application or container image and it's been exploited, if your Kubernetes environment is properly hardened, there is no container escape for the attacker to use to move laterally and continue escalating privilege. This can also be true against the blast radius of attacks that find initial footholds in the public cloud, web apps or elsewhere.
Security can enlist engineering in problem-solving
Kubernetes also lends itself to drawing engineering into the problem-solving process and giving security better signals, so the two teams can improve their cooperation.
- Harden & Detect: Kubernetes has tentacles in both the development arena and CI/CD pipeline as well as the running workloads, so you are in a natural position to put in guardrails for engineering as well as detect and respond.
Kubernetes is also the one place where the most number of developers and engineers are present and active, making engineering leaders very keen to get security guardrails for the rest of their team in place. There is not enough Kubernetes expertise to go around, so teams need to add people to the workflow who may not be experts. This draws engineering leadership into the problem-solving process for Kubernetes security.
Furthermore, per the points above, security can provide engineering with incredible context in order to make breaking changes, like admission control, only where needed.
Today Kubernetes is sidelined in security
Despite the opportunity we see for Kubernetes to improve efficiencies in cloud native security, in the market other vendors treat Kubernetes as a peripheral capability. This is true despite the fact that it is treated as a central initiative on the engineering side.
KSPM is a classic example, because, even though it is meant specifically for a Kubernetes environment, it is done on polling intervals disconnected from the Kubernetes lifecycle. Any team trying to remediate an issue found on a polling interval will struggle to understand what is actually happening, as the workloads and their associated configurations change in real-time.
Role-based access control, though a critically important security capability of Kubernetes, is either omitted altogether from the KSPM capabilities or addressed as a silo. The best tools for RBAC will provide a laundry list of overly permissive RBAC policies, with no context or connection to other Kubernetes components like the network or container vulnerabilities.
Admission controllers can sometimes only prevent workloads from running based on CVEs in the container images; not even including Kubernetes configurations in the list of criteria. Other admission controllers that have a broader policy set do not have a way to truly test if the tool will break production ahead of time; so engineering has no way to understand where the policies would apply without actually enforcing them.
Multiple breaches and attacks have been noted in the industry that involved Kubernetes, including the Dero cryptocurrency miner and RBAC-buster. In the Dero miner research, it is clear that the researchers first got their indication that something was wrong from a runtime perspective, and then performed reverse-engineering to understand that Kubernetes was involved. But attackers are targeting vulnerable Kubernetes environments from the start. Incidents involving or targeting Kubernetes must be detected from Kubernetes first, if they are to be detected in time.
A Kubernetes-first view of cloud native security
A Kubernetes-first view of cloud native security applies the natural advantages of Kubernetes to solve for inefficiencies in cloud native security. KSOC is the first in the industry to take this perspective, launching threat vectors that make Automated Risk Triage possible by highlighting critical risk based on connected Kubernetes components. A Kubernetes-first approach has key criteria to meet in order to improve efficiency.
- First, it has to tie a broad set of Kubernetes-connected components to the Kubernetes lifecycle and API, including Kubernetes configurations, RBAC container vulnerabilities, runtime, public cloud and the network. On its own, this wouldn’t be enough because you would have too much noise. The key is to use an understanding of the combined risk of these components to triage risk accurately and automatically. This should include visuals and open queries. See Automated Risk Triage in action today.
- Second, it has to take advantage of the guardrails in the CI process, use admission control for prevention, and detect security incidents through the lens of Kubernetes. If a goal is to put more control in the hands of engineering, a tool would have to become an extension of the Kubernetes footprint, so engineering doesn’t have to leave their CI tool of choice to see the policies set. Policies in the CI must be managed centrally across multiple clusters, and admission control must become something that can be trusted by engineering, with a way to understand what would happen in production if the policies are enforced. KSOC launched these capabilities along with Automated Risk Triage.
- Third, any detection would have to show that something is happening now, involving Kubernetes and its component parts, alongside guidance on how to most efficiently control the blast radius. See what this looks like in a live demo.
Reaching through all of this would have to be the same connected understanding of risk, to triage effectively what is relevant and not, using the context Kubernetes naturally provides. This would give engineering a clear ‘why’ for any asks to rework code and it would make the security team’s homework on this point easy and quick.
For anybody trying to show the environment is compliant at any given time, this prioritized understanding of risks would also be a game-changer. KSOC generates custom and standardized compliance reports across your Kubernetes environments, including an SBOM as well as a KBOM, which is similar concept to the SBOM but specific to Kubernetes configurations.
Conclusion
By embracing a Kubernetes-first approach to cloud native security you can take advantage of natural capabilities that contribute to better efficiency, such as real-time visibility, broad scope, built-in context and more. For more information, see how threat vectors can reduce the amount of time it takes for your busy engineering and infrastructure security to detect and understand their top risk in Kubernetes to your next coffee break. As teams are more short-staffed than ever, at KSOC we believe, and have demonstrated, that it is time to expect more from cloud native security in terms of efficiency and early detection of attacks targeting Kubernetes. To see Kubernetes-first cloud native security in action, sign up for our live demo or talk to the team today.
